이것만 보면 당신도 AWS MSK Standard Owner!
- 2024년 5월 7일
- 4분 분량
이것만 보면 당신도 AWS MSK Standard Owner!

Written by Minhyeok Cha
2부 아닌 2부입니다. 저번 블로그에서 말씀드렸듯 이번 글은 AWS MSK를 더욱 깊게 알아보고 Cluster 및 Connect를 구성까지 작성하려고 합니다.
▼ 지난 블로그 보러가기

MSK(Kafka)에서 사용되는 용어들

ZooKeeper
주키퍼는 브로커 관리를 위해 사용합니다.
브로커 상태 변경이 있는 경우 주키퍼가 프로듀서와 컨슈머에게 정보를 전달합니다.
Broker
브로커는 MSK 클러스터를 생성할 때 브로커 노드 수를 정하며 이는 클러스터 안에있는 서버입니다.
클러스터는 각 가용영역 당 하나씩의 브로커가 있으며 이는 프로듀서에서 컨슈머까지 메세지를 전달합니다.

Topic
데이터를 구분하는 가장 기본적인 단위입니다.
토픽에는 파티션이 존재 하는데, 파티션의 최소 1개는 있어야합니다.
Partition
키값으로 데이터를 구분하고 키값이 없을 경우 라운드 로빈 형식으로 데이터가 파티션에 저장됩니다.
offset
각 파티션마다 레코드(데이터) 위치를 배정합니다.
오프셋의 값은 파티션 내부에서 고유의 값으로 운용됩니다.
record
레코드는 데이터이며 타임스탬프 , 메세지 키 , 메세지 값 , 오프셋 , 헤더로 구성되어 있습니다.
이정도만 알아도 테스트 구축에는 문제없으니 바로 시작하겠습니다.
데모 1: MSK 구축 시작
구축은 AWS 서비스에서 2개만 생성할 예정입니다.
AWS MSK cluster - 카프카 브로커
Cloud9 - 프로듀서, 컨슈머용으로 메세지 전송 및 수신 확인
※ 전용 VPC 생성해서 진행하기 때문에 VPC 및 서비스 사전 생성AWS MSK Cluster

빠른 생성으로 하면 엄청 간단하긴 한데, 기본값(VPC, 서브넷, 가용 영역)으로 설정되는 것들이 많아서 사용자 지정으로 생성하겠습니다.




테스트 용이니 사양은 최소한 작게 사용합니다.
추가로 가용영역 = 2, 브로커 = 2로 총 4개의 브로커를 가지게 되며, 이는 2개의 AZ에 균등하게 배포됩니다.
Network

클러스터 생성 시 브로커의 영역을 2개로 설정했기 때문에 VPC 설정 후 내부 서브넷 2개를 지정합니다.

MSK 클러스터도 보안그룹이 들어가는데, 이때 이 보안그룹은 추가할 cloud9과 동일하게 사용해야 연결이 가능합니다.
Security

인증되지 않은 액세스를 사용하여 클라이언트에 대한 인증 작업 없이 허용하도록 합니다. 추가로 전송 데이터 및 저장 데이터의 암호화는 위와 같이 체크하시면 됩니다.
Monitoring

마찬가지로 기본 테스트나 기본 모니터링으로 설정하시면 됩니다.
이후 클러스터를 구성하면 되는데 생성에 20분 정도 잡아먹습니다.
20분간 cloud9 생성 및 카프카 앱을 설치하도록 하겠습니다.
Cloud9
서버생성




Cloud9의 구성은 엄청 간단하기 때문에 위 사진과 같이 해주세요.
주의사항으로는 VPC 설정을 하지 않으면 기본 VPC에 구성이 되기 때문에 MSK 클러스터를 생성한 곳과 같은 곳에서 생성해야 합니다.
EC2로 넘어가 Cloud9 역할 추가

FM으로 진행하려면 MSK arn 찍고 하나씩 권한부여를 해야하지만, 할 게 많으니 admin 하나 쥐어주고 넘어갑시다.
Cloud9 터미널 접근 후 다음 명령어 실행
$ sudo yum -y install java-11
$ wget https://archive.apache.org/dist/kafka/{YOUR MSK VERSION}/kafka_2.13-{YOUR MSK VERSION}.tgz
$ tar -xzf kafka_2.13-{YOUR MSK VERSION}.tgz
자바 및 아파치 카프카를 설치합니다. 이때 MSK 클러스터 버전과 동일하게 설치하는 것을 추천드립니다.
*테스트 해봤는데, 버전을 틀려도 연결은 문제가 없긴 했습니다.
$ cd kafka_2.13-{YOUR MSK VERSION}/libs
$ wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.1/aws-msk-iam-auth-1.1.1-all.jar
$ cd kafka_2.13-{YOUR MSK VERSION}/bin
$ vi client.properties
security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
Amazon MSK IAM JAR 파일을 다운로드 합니다. Amazon MSK IAM JAR을 사용하면 클라이언트 머신이 클러스터에 액세스 및 사용되는 보안 및 인증 구성을 정의합니다.
이후 MSK 클러스터가 생성되면 다음 명령어를 통해 간단한 topic 생성 및 producer에서 consumer로 메세지를 던져보겠습니다.
$ cd kafka_2.13-{YOUR MSK VERSION}/bin
$ ./kafka-topics.sh --create --bootstrap-server <MSK 클러스터 일반 텍스트> --command-config client.properties --replication-factor 2 --partitions 1 --topic MSKTutorialTopic
$ ./kafka-console-producer.sh --broker-list <MSK 클러스터 일반 텍스트> --producer.config client.properties --topic MSKTutorialTopic
# 터미널 추가 후 동일한 디렉터리에 들어가 실행
$ ./kafka-console-consumer.sh --bootstrap-server <MSK 클러스터 일반 텍스트> --consumer.config client.properties --topic MSKTutorialTopic --from-beginning

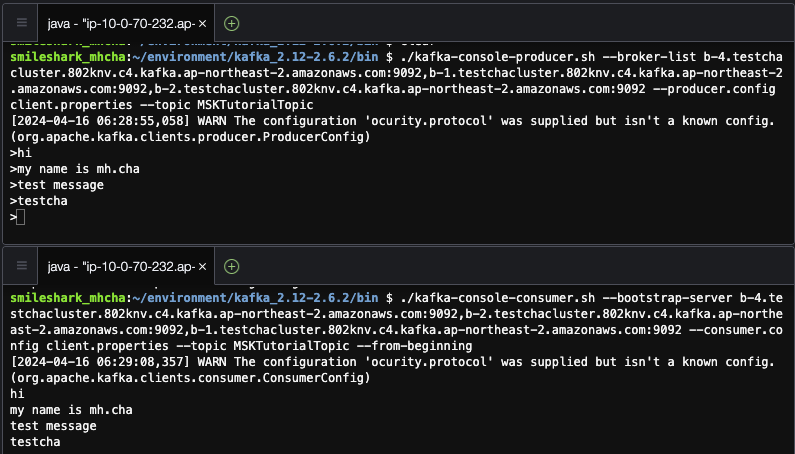
상단의 producer 터미널에서 아래 consumer 터미널로 메세지가 잘 전달되는 모습을 확인할 수 있습니다.
데모 2: MSK Connect 를 사용해 S3로 넘기기(S3 Sink Connector)
먼저 이 MSK Connect는 외부 시스템과 카프카 클러스터 사이에 데이터를 주고받기 쉽게 해주는 서비스입니다.
Kafka Connect 만 사용하여 CDC환경을 구축하면 상당히 많은 인프라 수작업을 필요로 하는데, MSK Connect를 사용하면 AWS Console 상에서 쉽게 Kafka Connect를 구성하고 배포 할 수 있습니다.

위 그림에서 보면 MSK 클러스터 양쪽에 MSK Connect가 있는데, 각각 Source Connector는 Producer의 역할 Sink Connector는 Consumer의 역할이라고 생각하시면 편합니다.
또한 MSK Connect를 사용하려면 플러그인이 필요한데 이 또한 여러가지의 오픈소스 (Debezium, Confluent 등등) 가 마련되어 있습니다.
우리의 목표는 인스턴스에서 받는 메세지로 MSK에서 S3까지가 목적이기 때문에 Amazon S3 Sink Connector 플러그인을 설치하여 데모를 진행하도록 하겠습니다.
※ 아키텍쳐상 MSK Sink Connetc에 해당하며 아래의 플러그인 설치 링크를 참고해 주세요.기존 MSK 클러스터 생성은 스킵하고 진행하도록 하겠습니다.
S3 버킷 생성
위 링크에서 받은 플러그인을 생성한 버킷에 업로드합니다.
이후 MSK Connect가 해당 버킷에 접근 권한을 부여하기 위한 IAM을 만들어야 합니다.
IAM 생성
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:DeleteObject"
],
"Resource": "<생성 버킷 ARN>"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucketMultipartUploads"
],
"Resource": "*"
}
]
}신뢰관계 형성
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kafkaconnect.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}위에서 생성한 역할을 S3 기반 롤로 생성합니다. 이때 신뢰관계에서 보이는 "Service"를 S3에서 kafkaconnect로 변경해야지 MSK Connect에서 해당 롤을 서치합니다.
S3 엔드포인트 게이트웨이

마지막으로 MSK에서 S3까지 데이터가 잘 흐를 수 있도록 S3 endpoint를 생성하여 배치해줍니다.
MSK Connect 플러그인 및 커넥터 생성

위의 S3에 업로드한 플러그인 압축파일까지 경로를 위 사진처럼 지정한 뒤 생성합니다.

위에서 만든 플러그인을 바로 커넥터 생성에 플러그인을 선택하여 생성해주도록 합니다.
커넥터 구성 필드


마지막으로 아까 만들어 둔 해당 MSK Connect가 S3 버킷 접근이 가능하도록 만든 역할을 넣습니다.
(MSK Connect도 MSK Cluster처럼 만드는데 시간이 좀 걸립니다.)
마지막으로 Cloud9에 들어와 kafka/bin 디렉터리에 client.properties 텍스트 파일을 생성하고 다음 내용을 삽입합니다.
security.protocol=PLAINTEXT이는 Kafka 클러스터와의 통신에 사용되는 보안 프로토콜을 지정하는 것입니다.
사전에 만든 클러스터가 일반 텍스트로 구성했기 때문에 "PLAINTEXT"라는 프로토콜을 기입하였습니다.
이후 producer를 통해 메세지를 3개 정도 보내보겠습니다.


3개의 보낸 메세지는 다음과 같이 S3에서 확인할 수 있습니다.
추가로 설명드릴 것은 S3 상단의 경로를 보시면 바로 json 메세지가 나오는게 아니라 여러 디렉토리를 경유해서 도착한 것을 보실 수 있을 것입니다.
이는 MSK Connect 구성의 topics.dir=testchamsk의 디렉토리를 생성하여 주제 및 클러스터를 구분시켜 두었기 때문입니다.
뿐만 아니라 MSK Connect 구성 필드는 다음 플러그인 링크를 통해 커스텀하여 사용할 수 있습니다.
마무리
원래는 AWS MSK 모두가 알다 시피 오픈소스 기반이기 때문에 EC2에 kafka를 직접 설치해서 사용하는 것과 MSK를 통해 사용하는 방법의 비용차이도 확인해 볼 계획까지도 잡아 두었는데 내용이 데모가 기준이다 보니까 넣지를 못했네요.
뿐만 아니라 콘솔 및 클러스터 단의 수준이 아니라 더욱 나가 데이터 레코드, 오프셋 설정 등 못한게 아쉽습니다.
분량 조절 실패…
추가로 S3 Sink Connector를 하면서 알게된 사실이지만 커넥터를 생성하는 것보다 작년에 출시된 Amazon MSK, Kinesis Data Firehose를 통해 Kafka 토픽 S3 전송 기능이 나왔더라고요. 굳이 플러그인을 설치하지 않아도 AWS 내부에서 전부 해결해 준다는 점이 편리할 것 같습니다.
다음 주제로는 이어서 Kinesis로 찾아뵙도록 하겠습니다.





